
ビデオの尺が数分から1時間、2時間と長くなると、字幕制作の難易度は飛躍的に高まります。認識すべきテキストの量が増え、話すスピードが大きく変化し、文の構造が複雑になり、タイムラインのずれの影響を受けやすくなります。その結果、より安定した、より精度の高いソリューション、つまり、字幕制作を行うクリエイター、コース開発者、ポッドキャストチームを求める人が増えています。 長い動画のためのAI字幕ジェネレーター. 大容量ファイルを高速に処理するだけでなく、動画全体を通して完璧な同期と意味の一貫性を維持する必要があります。コンテンツのアクセシビリティ向上、視聴体験の向上、あるいは多言語対応字幕の提供を目指すユーザーにとって、信頼性の高いAI字幕生成ワークフローは、効率性の向上だけでなく、コンテンツの品質確保にも不可欠です。.
目次
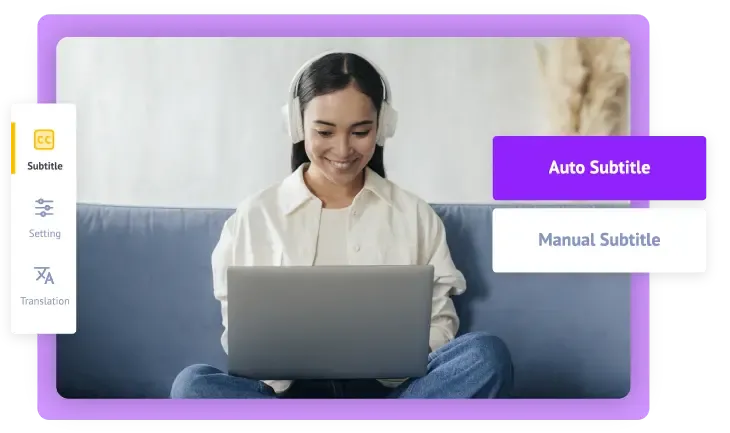
長尺動画には専用のAI字幕ジェネレーターが必要
長編動画の字幕生成における課題は、短編動画とは全く異なります。まず、長編動画の音声コンテンツはより複雑です。動画の長さが長くなるほど、話者の発話速度、イントネーション、明瞭度が変化する可能性が高くなります。この「スピーチドリフト」は、AI の認識精度に直接影響します。次に、長編動画には、講義のページめくりの音、インタビューの周囲の雑音、会議録音のキーボードのクリック音など、複数の背景ノイズが含まれることが多く、これらはすべて音声波形の解析を困難にします。同時に、長編動画の文章構造ロジックの処理はより困難です。AI はコンテンツを認識するだけでなく、数十分、あるいは数時間に及ぶ音声の中で文章の境界を正確に識別する必要があります。さらに、長編動画の音声品質は多くの場合一貫していません。Zoom、Teams、教室の録音などのソースは、音量レベルが不均一であったり、音声が過度に圧縮されていたりする可能性があり、認識がさらに複雑になります。.
その結果、標準的なキャプションツールは、1時間を超える動画を処理する際に、吃音、単語のスキップ、遅延、タイムラインのズレ、または完全なクラッシュなどの問題が頻繁に発生します。すべてのAIキャプションツールが1時間を超える動画を確実にサポートしているわけではありません。そのため、多くのユーザーが長尺動画に最適化されたソリューションを求めています。.
長尺動画用AI字幕ジェネレーターでユーザーが重視するポイント
1.字幕の正確さ
- 長い動画ではミスが蓄積し、校正コストが増大する。.
- アクセント、背景雑音、録音品質、発話速度の違い、複数の話者による発話は、すべて認識精度に影響する。.
- ツールには、より強力なノイズ除去機能、文のセグメンテーション機能、文脈理解機能が求められる。.
2.処理時間
- ユーザーは、1時間のビデオが5~20分以内に書き起こされることを期待している。.
- 処理速度の低下や障害は、ユーザー・エクスペリエンスを直接的に低下させる。.
- 安定したサーバーと効率的な推論能力は非常に重要だ。.
3.ロングビデオの互換性
- 無料のツールでは10~20分が上限となることが多く、長い動画はアップロードに失敗する。.
- ユーザーは、1~3時間以上のビデオを確実に処理するツールを求めている。.
- 処理中のクラッシュやコンテンツの損失はありません。.
4.タイムラインの調整
- 長いビデオは字幕の遅れや進みが起こりやすい。.
- ユーザーは、字幕が “前半は正確だが後半はずれている ”ことを恐れている。”
- 強制アライメントとタイムライン修正メカニズムが同期の質を高める。.
5.多言語字幕
- コース、講義、インタビューでは、多言語字幕が必要になることが多い。.
- ユーザーは、ワンクリック翻訳とバイリンガル字幕エクスポートを期待しています。.
- 多言語機能は、長編ビデオツールにとって大きな利点である。.
6.編集のしやすさ
- 長いビデオは字幕の量も多く、校正に時間がかかる。.
- ユーザーは、一括編集、迅速な文の分割、行の結合などの機能を必要とする。.
- ポストプロダクションの効率を高めるためには、エディターは安定していてラグがない必要がある。.
長尺動画におけるAI字幕ジェネレーターの仕組み
1~2時間のビデオの字幕を生成するには、AIは短いビデオよりも複雑な技術的プロセスを経なければなりません。以下の手順により、字幕が生成されるだけでなく、長時間のタイムラインでも安定性、正確性、同期性が保たれます。.
a.音声セグメンテーション
長い動画を処理する際、AIは音声ファイル全体を一度にモデルに入力しません。そうすることで、ファイルサイズの制限により、認識に失敗したり、サーバーがタイムアウトしたりするリスクがあるからです。その代わりに、システムはまず、意味的な意味や時間に基づいて、音声を数秒から数十秒ずつのより小さなセグメントに分割します。これにより、認識タスクの安定した実行が保証される。また、分割することでメモリ使用量も削減され、モデルを効率的に動作させることができる。.
b.自動音声認識(ASR)モデル
音声のセグメンテーションが終わると、AIは音声をテキストに変換するコアステップに進む。業界標準モデルには、Transformer、wav2vec 2.0、Whisperなどがあります。.

- 変圧器 英語のような主流言語では安定した性能を発揮するが、アクセントの変化には敏感だ。.
- wav2vec 2.0 低ノイズ環境に優れているため、講義やインタビューのような長時間のビデオに適している。.
- ささやき は、優れたバックグラウンドノイズ処理と多言語サポートを提供し、長時間のビデオシナリオで優位性を発揮します。.
モデルの違いにより、長いビデオの認識精度に顕著なばらつきが生じる。より高度なモデルは、発話速度の変動、一時停止、小さなノイズなどの詳細をより適切に管理します。.
字幕は連続したテキストではなく、意味ごとに分割された短いセグメントです。短い動画であれば文の分割は比較的簡単ですが、長い動画では、口調の変化、長時間の発話による疲労、論理的な遷移などにより、分割が難しくなります。AIは、発話の休止、意味構造、確率モデルに基づいて、改行や文の結合のタイミングを判断します。より正確な分割により、編集後の作業負担が軽減されます。.
d.強制アライメント
テキスト認識が完璧でも、キャプションが音声と同期しないことがあります。長い動画は特に、「最初は正確で、後でずれる」という問題が起こりがちです。この問題に対処するため、AIは強制アライメント技術を採用し、認識されたテキストを音声トラックと一字一句一致させます。この処理はミリ秒単位の精度で行われ、動画全体を通して一貫した字幕のタイミングを確保します。.
e.言語モデルの修正
長時間のビデオには、文脈的なつながりが強いという明確な特徴がある。例えば、講義では同じ核となる概念を繰り返し探求することがある。字幕の一貫性を高めるために、AIは認識後の二次補正に言語モデルを採用しています。このモデルは、文脈に基づいて、特定の単語を置き換えるか、統合するか、調整するかを評価します。このステップにより、長編動画キャプションの流暢さと専門性が大幅に向上します。.
長い動画のためのAI字幕ジェネレーターとしてのEasySub
長いビデオのサブタイトル生成において、EasySubは単なるスピードや自動化よりも安定性と制御性を優先しています。以下の機能により、1~3時間のビデオを処理する際に安定したパフォーマンスを保証し、講義、インタビュー、ポッドキャスト、チュートリアルなどの長時間のコンテンツに適しています。.
より長いビデオ処理時間のサポート
EasySubは、1時間、2時間、あるいはそれ以上の長時間のビデオファイルにも確実に対応します。録画された講義、会議録、長時間のインタビューなど、アップロード後の連続認識も、よくある中断やタイムアウトを起こすことなく完了します。.
高効率処理速度
ほとんどの場合、EasySubはサーバーの負荷とモデルの最適化戦略に基づいて並列処理を採用しています。.
60分のビデオは通常、5~12分以内に完全なサブタイトルを生成します。長いビデオは、この速度でも高い安定性と出力の一貫性を維持します。.
精度のための多層最適化
EasySubは長時間のビデオのために、多言語ASR、マイルドな自動ノイズリダクション、学習済みのセンテンスセグメンテーションモデルなど、複数の認識と最適化のストラテジーを採用しています。この組み合わせにより、バックグラウンドノイズの干渉を低減し、長時間の連続音声の認識精度を向上させます。.
合理化された編集エクスペリエンス
長編動画の字幕は、多くの場合、手作業による校正が必要です。EasySubのエディターは、一括編集、素早い文章分割、ワンクリックでの結合、段落プレビューをサポートしています。.
インターフェイスは、何千もの字幕を使用しても応答性を維持し、長いビデオの手動編集時間を最小限に抑えます。.
多言語およびバイリンガル字幕サポート
コース、講義、地域を超えたインタビューなどでは、ユーザーはしばしばバイリンガルまたは多言語の字幕を作成する必要があります。.
ソース言語の字幕を作成した後、EasySubはそれらを英語、スペイン語、ポルトガル語などの多言語に展開することができます。また、国際的なコンテンツバージョンを作成するためのバイリンガルエクスポートもサポートしています。.
ビルトイン タイムライン アライメント
長いビデオで最も一般的な問題は、“終盤になるほど字幕の同期が取れなくなる ”ことです。これを防ぐために、EasySubはタイムライン修正メカニズムを組み込んでいます。認識後、字幕とオーディオトラック間の正確な再調整を行い、ドリフトすることなくビデオ全体を通して一貫した字幕タイミングを確保します。.
長い動画の正確な字幕を生成するためのステップバイステップのワークフロー
長い動画のサブタイトルを作成する際の最大の課題は、複雑でミスの起こりやすいワークフローをナビゲートすることです。そのため、明確で実行可能なステップバイステップのガイドは、ユーザーがプロセス全体をすばやく把握し、エラー率を減らすのに役立ちます。以下のワークフローは、講義、インタビュー、会議、ポッドキャストなど、1~2時間以上のビデオ録画に適用されます。.
1.動画ファイルのアップロード(mp4 / mov / mkv / スクリーン録画)
.png)
ビデオを字幕作成プラットフォームにアップロードします。長い動画ファイルは一般的に大きいので、アップロードが中断されないよう、安定したインターネット接続を確保してください。ほとんどの専門的な字幕作成ツールは、mp4、mov、mkvなどの一般的な形式をサポートしており、Zoom、Teams、または携帯電話の画面録画からの動画も扱うことができます。.
2.自動ノイズ除去および音声明瞭度検出
認識前に、システムは音声にマイルドなノイズ除去を適用し、全体的な明瞭度を評価します。このステップは、認識結果に対する背景ノイズの影響を効果的に最小化します。長いビデオではノイズのパターンが異なるため、この処理により、後続の字幕の安定性と精度が向上します。.
3.認識言語または多言語モデルを選択
ユーザーは、ビデオの内容に基づいて主要言語モデルを選択することができます。例えば英語、スペイン語、ポルトガル語、多言語モード。2つの言語が混在するインタビュー形式のビデオでは、多言語モデルが認識の流暢さを維持し、聞き漏らしを最小限に抑えます。.
4.AIの自動認識を開始し、文のセグメンテーションを生成する。
AIは認識のために音声をセグメンテーションし、意味的な意味と発声の休止に基づいた文の区切りを適用して、字幕原稿を自動的に生成する。長い動画では、より複雑なセグメンテーション・ロジックが必要になります。専門的なモデルが自動的に改行を決定し、編集後の作業負荷を軽減します。.
5.字幕の校正、タイムラインの調整、長い文章の結合
-1024x598.png)
生成後、素早く字幕を確認する:
- タイムラインの同期を確認する
- 過度に短い字幕行をマージする
- 不要な文の区切りを調整する
- 特定の名詞、用語、独自の用語を修正する。
長い動画では、しばしば「前半は正確で、後半がずれている」という問題が起こります。プロフェッショナルなツールには、このようなズレを最小限に抑えるタイムライン補正機能があります。.
6.希望のフォーマットで書き出す:SRT / VTT / MP4 組み込み字幕
編集後、字幕ファイルをエクスポートします。一般的なフォーマットは以下の通りです:
- SRT:最も普遍的で、ほとんどのプレーヤーと互換性がある
- VTT:ウェブプレーヤーや学習プラットフォームに最適
- MP4埋め込み字幕:ソーシャルメディアやビデオコースシステムへの直接公開に最適
YouTube、Vimeo、またはコースのプラットフォームに公開する場合は、それぞれの要件を満たすフォーマットを選択してください。.
ユースケース:長い動画に本当にAI字幕が必要なのは誰か?
| ユースケース | 実際のユーザーのペインポイント |
|---|---|
| YouTubeと教育クリエイター | 長尺の教育用ビデオは字幕のボリュームが膨大で、手作業での制作は現実的ではありません。クリエイターは、視聴体験を向上させるために、安定したタイムラインと高い精度を要求する。. |
| オンラインコース(1~3時間) | コースには多くの専門用語が含まれ、不正確なセグメンテーションは学習に影響を与えます。インストラクターには、高速で編集可能な字幕と多言語オプションが必要です。. |
| ポッドキャストとインタビュー | 長時間の会話では、音声のスピードが安定せず、認識エラーも多くなります。クリエイターは、編集や出版のために、高速で全文の字幕を求めています。. |
| Zoom / チームミーティングの録画 | 複数のスピーカーが重複しているため、共通のツールではエラーが発生しやすい。ユーザーは、素早く生成され、検索可能で、アーカイブ可能な字幕コンテンツを必要としています。. |
| 学術講演会 | アカデミックな語彙が多く、長いビデオを正確に書き写すのは難しい。学生は復習やノートの整理に正確な字幕を頼りにしています。. |
| 法廷音声/調査インタビュー | 長い期間と厳しい精度要件。認識ミスがあれば、文書化や法的解釈に影響を及ぼす可能性がある。. |
| ドキュメンタリー | 複雑な環境ノイズがAIモデルを容易に混乱させる。プロデューサーはポストプロダクションや国際配信のために安定した長時間のタイムライン同期を必要としている。. |
長尺動画字幕生成の精度ベンチマーク
長尺映像のシナリオでは、字幕ツールの性能に大きなばらつきがあります。モデル機能、ノイズ除去の効果、センテンス セグメンテーション ロジックはすべて、最終的な字幕品質に直接影響します。以下は、業界内で一般的に参照されている精度の範囲であり、長編ビデオの字幕生成パフォーマンスを理解するための参考資料となります。.
業界基準精度
- ウィスパー・ラージ-v3:約95%(多言語および低ノイズシナリオで一貫した性能)
- 市販の一般的な無料ツール:約80-90%(バックグラウンドノイズやアクセントの影響を受けやすい)
- 人力字幕(手書き文字起こし):100%に近づく(しかしコストと時間がかかる)
これらの数値はあらゆるシナリオを網羅しているわけではありませんが、重要な事実を浮き彫りにしています。それは、高い認識精度を達成するのは、短い動画よりも長い動画の方が難しいということです。長い動画では、発話速度の変化がより顕著になり、背景ノイズも複雑になり、時間の経過とともにエラーが蓄積されるため、編集後の作業時間が大幅に増加します。.
長尺動画で精度がより重要になる理由
- 映像の長さに応じてエラーは蓄積され、編集時間は指数関数的に長くなる。.
- マルチセグメント録音における音質のばらつきは、認識の不安定性を引き起こす。.
- 後半の字幕は遅延やズレが生じやすく、視聴体験を損なう。.
- コース、講義、インタビューなどの長文コンテンツには、固有名詞が多数含まれることが多く、より高い精度が要求されます。.
イージーサブの社内テスト結果
長尺シナリオでのパフォーマンスを評価するため、多様な実世界の素材を使用した社内テストを実施した。その結果 60~90分 ビデオでは、EasySubは全体的な精度を達成しています。 業界をリードするモデルに迫る 専門用語や連続音声処理で安定したパフォーマンスを維持しながら。.
FAQ — 長編動画向けAI字幕
Q1.AIが生成するキャプションは、長い動画に対してどの程度の精度がありますか?
精度は通常85%から95%の範囲で、音質、話者のアクセント、背景雑音、ビデオの種類によって異なります。長時間の動画は、短い動画に比べて、時間が長く、発話速度が異なるため、より大きな問題が発生します。したがって、生成後にキャプションを校正することをお勧めします。.
Q2.EasySubで扱えるビデオの長さはどれくらいですか?
EasySubは1時間、2時間、あるいはそれ以上の長時間の動画処理をサポートし、画面録画、講義、会議などの大容量ファイルを確実に処理します。実用的な上限はファイルサイズとアップロード速度に依存します。.
Q3.1時間のビデオの字幕を作成するのに、どれくらいの時間がかかりますか?
通常5~12分で完了します。実際の所要時間は、サーバーの負荷、音声の複雑さ、多言語処理の要件によって異なる場合があります。.
Q4.どのような字幕やビデオファイル形式に対応していますか?
一般的なビデオフォーマットには、mp4、mov、mkv、webm、画面録画ファイルなどがあります。字幕のエクスポート形式は、通常、SRT、VTT、および字幕を埋め込んだMP4ファイルをサポートしており、さまざまなプラットフォームのアップロード要件に対応しています。.
Q5.生成後に手作業による校正は必要ですか?
特に、専門用語、固有名詞、アクセントの強い発話、複数話者による対話については、基本的な確認を行うことをお勧めします。AIは作業量を大幅に削減しますが、人間による検証は、最終的なアウトプットの正確性と専門性をより確実にします。.
長い動画に正確な字幕を
高品質のキャプションは、長編ビデオの読みやすさと専門性を大幅に高めます。ビデオをアップロードすると自動的にキャプションが生成され、必要に応じてすばやく校正して書き出すことができます。コースの録画、会議の議事録、インタビューコンテンツ、長時間のインストラクションビデオに最適です。.
長編動画コンテンツの明瞭さとインパクトをさらに向上させたい場合は、自動キャプション生成から始めてみましょう。.
👉無料トライアルはこちらをクリックしてください: easyssub.com
このブログを読んでいただきありがとうございます。. ご質問やカスタマイズのご要望がございましたら、お気軽にお問い合わせください。




